A simple description of the UNIX system, also applicable to Linux, is this:
“On a UNIX system, everything is a file; if something is not a file, it is a process.”
This statement is true because there are special files that are more than just files (named pipes and sockets, for instance), but to keep things simple, saying that everything is a file is an acceptable generalization. A Linux system, just like UNIX, makes no difference between a file and a directory, since a directory is just a file containing names of other files. Programs, services, texts, images, and so forth, are all files. Input and output devices, and generally all devices, are considered to be files, according to the system.
In order to manage all those files in an orderly fashion, man likes to think of them in an ordered tree-like structure on the hard disk, as we know from MS-DOS (Disk Operating System) for instance. The large branches contain more branches, and the branches at the end contain the tree's leaves or normal files. For now we will use this image of the tree, but we will find out later why this is not a fully accurate image.
Most files are just files, called regular files; they contain normal data, for example text files, executable files or programs, input for or output from a program and so on.
While it is reasonably safe to suppose that everything you encounter on a Linux system is a file, there are some exceptions.
Special files: the mechanism used for input and output. Most special files are in
/dev, we will discuss them later.Links: a system to make a file or directory visible in multiple parts of the system's file tree. We will talk about links in detail.
(Domain) sockets: a special file type, similar to TCP/IP sockets, providing inter-process networking protected by the file system's access control.
Named pipes: act more or less like sockets and form a way for processes to communicate with each other, without using network socket semantics.
The -l option to ls displays the file type, using the first character of each input line:
jaime:~/Documents> ls -l
total 80
-rw-rw-r-- 1 jaime jaime 31744 Feb 21 17:56 intro Linux.doc
-rw-rw-r-- 1 jaime jaime 41472 Feb 21 17:56 Linux.doc
drwxrwxr-x 2 jaime jaime 4096 Feb 25 11:50 course
This table gives an overview of the characters determining the file type:
In order not to always have to perform a long listing for seeing the file type, a lot of systems by default don't issue just ls, but ls -F, which suffixes file names with one of the characters “/=*|@” to indicate the file type. To make it extra easy on the beginning user, both the -F and --color options are usually combined, see Section 3.1.1, “More about ls”. We will use ls -F throughout this document for better readability.
As a user, you only need to deal directly with plain files, executable files, directories and links. The special file types are there for making your system do what you demand from it and are dealt with by system administrators and programmers.
Now, before we look at the important files and directories, we need to know more about partitions.
Most people have a vague knowledge of what partitions are, since every operating system has the ability to create or remove them. It may seem strange that Linux uses more than one partition on the same disk, even when using the standard installation procedure, so some explanation is called for.
One of the goals of having different partitions is to achieve higher data security in case of disaster. By dividing the hard disk in partitions, data can be grouped and separated. When an accident occurs, only the data in the partition that got the hit will be damaged, while the data on the other partitions will most likely survive.
This principle dates from the days when Linux didn't have journaled file systems and power failures might have lead to disaster. The use of partitions remains for security and robustness reasons, so a breach on one part of the system doesn't automatically mean that the whole computer is in danger. This is currently the most important reason for partitioning. A simple example: a user creates a script, a program or a web application that starts filling up the disk. If the disk contains only one big partition, the entire system will stop functioning if the disk is full. If the user stores the data on a separate partition, then only that (data) partition will be affected, while the system partitions and possible other data partitions keep functioning.
Mind that having a journaled file system only provides data security in case of power failure and sudden disconnection of storage devices. This does not protect your data against bad blocks and logical errors in the file system. In those cases, you should use a RAID (Redundant Array of Inexpensive Disks) solution.
There are two kinds of major partitions on a Linux system:
Most systems contain a root partition, one or more data partitions and one or more swap partitions. Systems in mixed environments may contain partitions for other system data, such as a partition with a FAT or VFAT file system for MS Windows data.
Most Linux systems use fdisk at installation time to set the partition type. As you may have noticed during the exercise from Chapter 1, this usually happens automatically. On some occasions, however, you may not be so lucky. In such cases, you will need to select the partition type manually and even manually do the actual partitioning. The standard Linux partitions have number 82 for swap and 83 for data, which can be journaled (ext3) or normal (ext2, on older systems). The fdisk utility has built-in help, should you forget these values.
Apart from these two, Linux supports a variety of other file system types, such as the relatively new Reiser file system, JFS, NFS, FATxx and many other file systems natively available on other (proprietary) operating systems.
The standard root partition (indicated with a single forward slash, /) is about 100-500 MB, and contains the system configuration files, most basic commands and server programs, system libraries, some temporary space and the home directory of the administrative user. A standard installation requires about 250 MB for the root partition.
Swap space (indicated with swap) is only accessible for the system itself, and is hidden from view during normal operation. Swap is the system that ensures, like on normal UNIX systems, that you can keep on working, whatever happens. On Linux, you will virtually never see irritating messages like Out of memory, please close some applications first and try again, because of this extra memory. The swap or virtual memory procedure has long been adopted by operating systems outside the UNIX world by now.
Using memory on a hard disk is naturally slower than using the real memory chips of a computer, but having this little extra is a great comfort. We will learn more about swap when we discuss processes in Chapter 4, Processes.
Linux generally counts on having twice the amount of physical memory in the form of swap space on the hard disk. When installing a system, you have to know how you are going to do this. An example on a system with 512 MB of RAM:
1st possibility: one swap partition of 1 GB
2nd possibility: two swap partitions of 512 MB
3rd possibility: with two hard disks: 1 partition of 512 MB on each disk.
The last option will give the best results when a lot of I/O is to be expected.
Read the software documentation for specific guidelines. Some applications, such as databases, might require more swap space. Others, such as some handheld systems, might not have any swap at all by lack of a hard disk. Swap space may also depend on your kernel version.
The kernel is on a separate partition as well in many distributions, because it is the most important file of your system. If this is the case, you will find that you also have a /boot partition, holding your kernel(s) and accompanying data files.
The rest of the hard disk(s) is generally divided in data partitions, although it may be that all of the non-system critical data resides on one partition, for example when you perform a standard workstation installation. When non-critical data is separated on different partitions, it usually happens following a set pattern:
a partition for user programs (/usr)
a partition containing the users' personal data (/home)
a partition to store temporary data like print- and mail-queues (/var)
a partition for third party and extra software (/opt)
Once the partitions are made, you can only add more. Changing sizes or properties of existing partitions is possible but not advisable.
The division of hard disks into partitions is determined by the system administrator. On larger systems, he or she may even spread one partition over several hard disks, using the appropriate software. Most distributions allow for standard setups optimized for workstations (average users) and for general server purposes, but also accept customized partitions. During the installation process you can define your own partition layout using either your distribution specific tool, which is usually a straight forward graphical interface, or fdisk, a text-based tool for creating partitions and setting their properties.
A workstation or client installation is for use by mainly one and the same person. The selected software for installation reflects this and the stress is on common user packages, such as nice desktop themes, development tools, client programs for E-mail, multimedia software, web and other services. Everything is put together on one large partition, swap space twice the amount of RAM is added and your generic workstation is complete, providing the largest amount of disk space possible for personal use, but with the disadvantage of possible data integrity loss during problem situations.
On a server, system data tends to be separate from user data. Programs that offer services are kept in a different place than the data handled by this service. Different partitions will be created on such systems:
a partition with all data necessary to boot the machine
a partition with configuration data and server programs
one or more partitions containing the server data such as database tables, user mails, an ftp archive etc.
a partition with user programs and applications
one or more partitions for the user specific files (home directories)
one or more swap partitions (virtual memory)
Servers usually have more memory and thus more swap space. Certain server processes, such as databases, may require more swap space than usual; see the specific documentation for detailed information. For better performance, swap is often divided into different swap partitions.
All partitions are attached to the system via a mount point. The mount point defines the place of a particular data set in the file system. Usually, all partitions are connected through the root partition. On this partition, which is indicated with the slash (/), directories are created. These empty directories will be the starting point of the partitions that are attached to them. An example: given a partition that holds the following directories:
videos/ cd-images/ pictures/
We want to attach this partition in the filesystem in a directory called /opt/media. In order to do this, the system administrator has to make sure that the directory /opt/media exists on the system. Preferably, it should be an empty directory. How this is done is explained later in this chapter. Then, using the mount command, the administrator can attach the partition to the system. When you look at the content of the formerly empty directory /opt/media, it will contain the files and directories that are on the mounted medium (hard disk or partition of a hard disk, CD, DVD, flash card, USB or other storage device).
During system startup, all the partitions are thus mounted, as described in the file /etc/fstab. Some partitions are not mounted by default, for instance if they are not constantly connected to the system, such like the storage used by your digital camera. If well configured, the device will be mounted as soon as the system notices that it is connected, or it can be user-mountable, i.e. you don't need to be system administrator to attach and detach the device to and from the system. There is an example in Section 3, “Using rsync”.
On a running system, information about the partitions and their mount points can be displayed using the df command (which stands for disk full or disk free). In Linux, df is the GNU version, and supports the -h or human readable option which greatly improves readability. Note that commercial UNIX machines commonly have their own versions of df and many other commands. Their behavior is usually the same, though GNU versions of common tools often have more and better features.
The df command only displays information about active non-swap partitions. These can include partitions from other networked systems, like in the example below where the home directories are mounted from a file server on the network, a situation often encountered in corporate environments.
freddy:~> df -h
Filesystem Size Used Avail Use% Mounted on
/dev/hda8 496M 183M 288M 39% /
/dev/hda1 124M 8.4M 109M 8% /boot
/dev/hda5 19G 15G 2.7G 85% /opt
/dev/hda6 7.0G 5.4G 1.2G 81% /usr
/dev/hda7 3.7G 2.7G 867M 77% /var
fs1:/home 8.9G 3.7G 4.7G 44% /.automount/fs1/root/home
For convenience, the Linux file system is usually thought of in a tree structure. On a standard Linux system you will find the layout generally follows the scheme presented below.
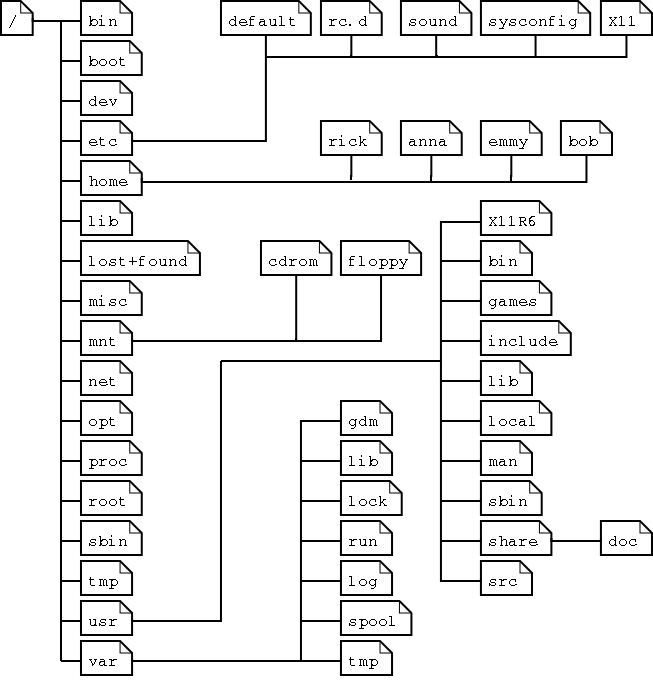
This is a layout from a RedHat system. Depending on the system admin, the operating system and the mission of the UNIX machine, the structure may vary, and directories may be left out or added at will. The names are not even required; they are only a convention.
The tree of the file system starts at the trunk or slash, indicated by a forward slash (/). This directory, containing all underlying directories and files, is also called the root directory or “the root” of the file system.
Directories that are only one level below the root directory are often preceded by a slash, to indicate their position and prevent confusion with other directories that could have the same name. When starting with a new system, it is always a good idea to take a look in the root directory. Let's see what you could run into:
emmy:~>cd /emmy:/>ls bin/ dev/ home/ lib/ misc/ opt/ root/ tmp/ var/ boot/ etc/ initrd/ lost+found/ mnt/ proc/ sbin/ usr/
Table 3.2. Subdirectories of the root directory
How can you find out which partition a directory is on? Using the df command with a dot (.) as an option shows the partition the current directory belongs to, and informs about the amount of space used on this partition:
sandra:/lib> df -h .
Filesystem Size Used Avail Use% Mounted on
/dev/hda7 980M 163M 767M 18% /
As a general rule, every directory under the root directory is on the root partition, unless it has a separate entry in the full listing from df (or df -h with no other options).
For most users and for most common system administration tasks, it is enough to accept that files and directories are ordered in a tree-like structure. The computer, however, doesn't understand a thing about trees or tree-structures.
Every partition has its own file system. By imagining all those file systems together, we can form an idea of the tree-structure of the entire system, but it is not as simple as that. In a file system, a file is represented by an inode, a kind of serial number containing information about the actual data that makes up the file: to whom this file belongs, and where is it located on the hard disk.
Every partition has its own set of inodes; throughout a system with multiple partitions, files with the same inode number can exist.
Each inode describes a data structure on the hard disk, storing the properties of a file, including the physical location of the file data. When a hard disk is initialized to accept data storage, usually during the initial system installation process or when adding extra disks to an existing system, a fixed number of inodes per partition is created. This number will be the maximum amount of files, of all types (including directories, special files, links etc.) that can exist at the same time on the partition. We typically count on having 1 inode per 2 to 8 kilobytes of storage.
At the time a new file is created, it gets a free inode. In that inode is the following information:
Owner and group owner of the file.
File type (regular, directory, ...)
Permissions on the file Section 4.1, “Access rights: Linux's first line of defense”
Date and time of creation, last read and change.
Date and time this information has been changed in the inode.
Number of links to this file (see later in this chapter).
File size
An address defining the actual location of the file data.
The only information not included in an inode, is the file name and directory. These are stored in the special directory files. By comparing file names and inode numbers, the system can make up a tree-structure that the user understands. Users can display inode numbers using the -i option to ls. The inodes have their own separate space on the disk.