Now that we are more used to our environment and we are able to communicate a little bit with our system, it is time to study the processes we can start in more detail. Not every command starts a single process. Some commands initiate a series of processes, such as mozilla; others, like ls, are executed as a single command.
Furthermore, Linux is based on UNIX, where it has been common policy to have multiple users running multiple commands, at the same time and on the same system. It is obvious that measures have to be taken to have the CPU manage all these processes, and that functionality has to be provided so users can switch between processes. In some cases, processes will have to continue to run even when the user who started them logs out. And users need a means to reactivate interrupted processes.
We will explain the structure of Linux processes in the next sections.
Interactive processes are initialized and controlled through a terminal session. In other words, there has to be someone connected to the system to start these processes; they are not started automatically as part of the system functions. These processes can run in the foreground, occupying the terminal that started the program, and you can't start other applications as long as this process is running in the foreground. Alternatively, they can run in the background, so that the terminal in which you started the program can accept new commands while the program is running. Until now, we mainly focussed on programs running in the foreground - the length of time taken to run them was too short to notice - but viewing a file with the less command is a good example of a command occupying the terminal session. In this case, the activated program is waiting for you to do something. The program is still connected to the terminal from where it was started, and the terminal is only useful for entering commands this program can understand. Other commands will just result in errors or unresponsiveness of the system.
While a process runs in the background, however, the user is not prevented from doing other things in the terminal in which he started the program, while it is running.
The shell offers a feature called job control which allows easy handling of multiple processes. This mechanism switches processes between the foreground and the background. Using this system, programs can also be started in the background immediately.
Running a process in the background is only useful for programs that don't need user input (via the shell). Putting a job in the background is typically done when execution of a job is expected to take a long time. In order to free the issuing terminal after entering the command, a trailing ampersand is added. In the example, using graphical mode, we open an extra terminal window from the existing one:
billy:~>xterm & [1] 26558billy:~>jobs [1]+ Running xterm &
The full job control features are explained in detail in the bash Info pages, so only the frequently used job control applications are listed here:
Table 4.1. Controlling processes
More practical examples can be found in the exercises.
Most UNIX systems are likely to be able to run screen, which is useful when you actually want another shell to execute commands. Upon calling screen, a new session is created with an accompanying shell and/or commands as specified, which you can then put out of the way. In this new session you may do whatever it is you want to do. All programs and operations will run independent of the issuing shell. You can then detach this session, while the programs you started in it continue to run, even when you log out of the originating shell, and pick your screen up again any time you like.
This program originates from a time when virtual consoles were not invented yet, and everything needed to be done using one text terminal. To addicts, it still has meaning in Linux, even though we've had virtual consoles for almost ten years.
Automatic or batch processes are not connected to a terminal. Rather, these are tasks that can be queued into a spooler area, where they wait to be executed on a FIFO (first-in, first-out) basis. Such tasks can be executed using one of two criteria:
At a certain date and time: done using the at command, which we will discuss in the second part of this chapter.
At times when the total system load is low enough to accept extra jobs: done using the batch command. By default, tasks are put in a queue where they wait to be executed until the system load is lower than 0.8. In large environments, the system administrator may prefer batch processing when large amounts of data have to be processed or when tasks demanding a lot of system resources have to be executed on an already loaded system. Batch processing is also used for optimizing system performance.
Daemons are server processes that run continuously. Most of the time, they are initialized at system startup and then wait in the background until their service is required. A typical example is the networking daemon, xinetd, which is started in almost every boot procedure. After the system is booted, the network daemon just sits and waits until a client program, such as an FTP client, needs to connect.
A process has a series of characteristics, which can be viewed with the ps command:
The process ID or PID: a unique identification number used to refer to the process.
The parent process ID or PPID: the number of the process (PID) that started this process.
Nice number: the degree of friendliness of this process toward other processes (not to be confused with process priority, which is calculated based on this nice number and recent CPU usage of the process).
Terminal or TTY: terminal to which the process is connected.
User name of the real and effective user (RUID and EUID): the owner of the process. The real owner is the user issuing the command, the effective user is the one determining access to system resources. RUID and EUID are usually the same, and the process has the same access rights the issuing user would have. An example to clarify this: the browser mozilla in
/usr/binis owned by user root:theo:~>ls -l /usr/bin/mozilla -rwxr-xr-x 1 root root 4996 Nov 20 18:28 /usr/bin/mozilla*theo:~>mozilla & [1] 26595theo:~>ps -af UID PID PPID C STIME TTY TIME CMD theo 26601 26599 0 15:04 pts/5 00:00:00 /usr/lib/mozilla/mozilla-bin theo 26613 26569 0 15:04 pts/5 00:00:00 ps -afWhen user theo starts this program, the process itself and all processes started by the initial process, will be owned by user theo and not by the system administrator. When mozilla needs access to certain files, that access will be determined by theo's permissions and not by root's.
Real and effective group owner (RGID and EGID): The real group owner of a process is the primary group of the user who started the process. The effective group owner is usually the same, except when SGID access mode has been applied to a file.
The ps command is one of the tools for visualizing processes. This command has several options which can be combined to display different process attributes.
With no options specified, ps only gives information about the current shell and eventual processes:
theo:~> ps
PID TTY TIME CMD
4245 pts/7 00:00:00 bash
5314 pts/7 00:00:00 ps
Since this does not give enough information - generally, at least a hundred processes are running on your system - we will usually select particular processes out of the list of all processes, using the grep command in a pipe, see Section 1.2.1, “Output redirection with > and |”, as in this line, which will select and display all processes owned by a particular user:
ps -ef | grep username
This example shows all processes with a process name of bash, the most common login shell on Linux systems:
theo:> ps auxw | grep bash
brenda 31970 0.0 0.3 6080 1556 tty2 S Feb23 0:00 -bash
root 32043 0.0 0.3 6112 1600 tty4 S Feb23 0:00 -bash
theo 32581 0.0 0.3 6384 1864 pts/1 S Feb23 0:00 bash
theo 32616 0.0 0.3 6396 1896 pts/2 S Feb23 0:00 bash
theo 32629 0.0 0.3 6380 1856 pts/3 S Feb23 0:00 bash
theo 2214 0.0 0.3 6412 1944 pts/5 S 16:18 0:02 bash
theo 4245 0.0 0.3 6392 1888 pts/7 S 17:26 0:00 bash
theo 5427 0.0 0.1 3720 548 pts/7 S 19:22 0:00 grep bash
In these cases, the grep command finding lines containing the string bash is often displayed as well on systems that have a lot of idletime. If you don't want this to happen, use the pgrep command.
Bash shells are a special case: this process list also shows which ones are login shells (where you have to give your username and password, such as when you log in in textmode or do a remote login, as opposed to non-login shells, started up for instance by clicking a terminal window icon). Such login shells are preceded with a dash (-).
|?
We will explain about the | operator in the next chapter, see Chapter 5, I/O redirection.
More info can be found the usual way: ps --help or man ps. GNU ps supports different styles of option formats; the above examples don't contain errors.
Note that ps only gives a momentary state of the active processes, it is a one-time recording. The top program displays a more precise view by updating the results given by ps (with a bunch of options) once every five seconds, generating a new list of the processes causing the heaviest load periodically, meanwhile integrating more information about the swap space in use and the state of the CPU, from the proc file system:
12:40pm up 9 days, 6:00, 4 users, load average: 0.21, 0.11, 0.03
89 processes: 86 sleeping, 3 running, 0 zombie, 0 stopped
CPU states: 2.5% user, 1.7% system, 0.0% nice, 95.6% idle
Mem: 255120K av, 239412K used, 15708K free, 756K shrd, 22620K buff
Swap: 1050176K av, 76428K used, 973748K free, 82756K cached
PID USER PRI NI SIZE RSS SHARE STAT %CPU %MEM TIME COMMAND
5005 root 14 0 91572 15M 11580 R 1.9 6.0 7:53 X
19599 jeff 14 0 1024 1024 796 R 1.1 0.4 0:01 top
19100 jeff 9 0 5288 4948 3888 R 0.5 1.9 0:24 gnome-terminal
19328 jeff 9 0 37884 36M 14724 S 0.5 14.8 1:30 mozilla-bin
1 root 8 0 516 472 464 S 0.0 0.1 0:06 init
2 root 9 0 0 0 0 SW 0.0 0.0 0:02 keventd
3 root 9 0 0 0 0 SW 0.0 0.0 0:00 kapm-idled
4 root 19 19 0 0 0 SWN 0.0 0.0 0:00 ksoftirqd_CPU0
5 root 9 0 0 0 0 SW 0.0 0.0 0:33 kswapd
6 root 9 0 0 0 0 SW 0.0 0.0 0:00 kreclaimd
7 root 9 0 0 0 0 SW 0.0 0.0 0:00 bdflush
8 root 9 0 0 0 0 SW 0.0 0.0 0:05 kupdated
9 root -1-20 0 0 0 SW< 0.0 0.0 0:00 mdrecoveryd
13 root 9 0 0 0 0 SW 0.0 0.0 0:01 kjournald
89 root 9 0 0 0 0 SW 0.0 0.0 0:00 khubd
219 root 9 0 0 0 0 SW 0.0 0.0 0:00 kjournald
220 root 9 0 0 0 0 SW 0.0 0.0 0:00 kjournald
The first line of top contains the same information displayed by the uptime command:
jeff:~> uptime
3:30pm, up 12 days, 23:29, 6 users, load average: 0.01, 0.02, 0.00
The data for these programs is stored among others in /var/run/utmp (information about currently connected users) and in the virtual file system /proc, for example /proc/loadavg (average load information). There are all sorts of graphical applications to view this data, such as the Gnome System Monitor and lavaps. Over at FreshMeat and SourceForge you will find tens of applications that centralize this information along with other server data and logs from multiple servers on one (web) server, allowing monitoring of the entire IT infrastructure from one workstation.
The relations between processes can be visualized using the pstree command:
sophie:~> pstree
init-+-amd
|-apmd
|-2*[artsd]
|-atd
|-crond
|-deskguide_apple
|-eth0
|-gdm---gdm-+-X
| `-gnome-session-+-Gnome
| |-ssh-agent
| `-true
|-geyes_applet
|-gkb_applet
|-gnome-name-serv
|-gnome-smproxy
|-gnome-terminal-+-bash---vim
| |-bash
| |-bash---pstree
| |-bash---ssh
| |-bash---mozilla-bin---mozilla-bin---3*[mozilla-bin]
| `-gnome-pty-helper
|-gpm
|-gweather
|-kapm-idled
|-3*[kdeinit]
|-keventd
|-khubd
|-5*[kjournald]
|-klogd
|-lockd---rpciod
|-lpd
|-mdrecoveryd
|-6*[mingetty]
|-8*[nfsd]
|-nscd---nscd---5*[nscd]
|-ntpd
|-3*[oafd]
|-panel
|-portmap
|-rhnsd
|-rpc.mountd
|-rpc.rquotad
|-rpc.statd
|-sawfish
|-screenshooter_a
|-sendmail
|-sshd---sshd---bash---su---bash
|-syslogd
|-tasklist_applet
|-vmnet-bridge
|-xfs
`-xinetd-ipv6
The -u and -a options give additional information. For more options and what they do, refer to the Info pages.
In the next section, we will see how one process can create another.
A new process is created because an existing process makes an exact copy of itself. This child process has the same environment as its parent, only the process ID number is different. This procedure is called forking.
After the forking process, the address space of the child process is overwritten with the new process data. This is done through an exec call to the system.
The fork-and-exec mechanism thus switches an old command with a new, while the environment in which the new program is executed remains the same, including configuration of input and output devices, environment variables and priority. This mechanism is used to create all UNIX processes, so it also applies to the Linux operating system. Even the first process, init, with process ID 1, is forked during the boot procedure in the so-called bootstrapping procedure.
This scheme illustrates the fork-and-exec mechanism. The process ID changes after the fork procedure:
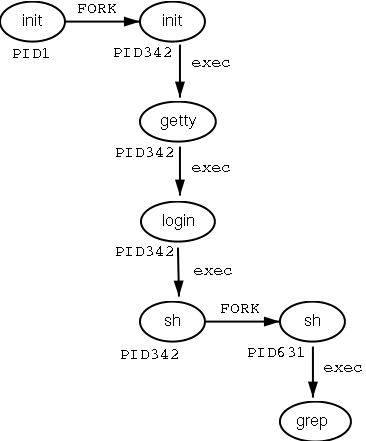
There are a couple of cases in which init becomes the parent of a process, while the process was not started by init, as we already saw in the pstree example. Many programs, for instance, daemonize their child processes, so they can keep on running when the parent stops or is being stopped. A window manager is a typical example; it starts an xterm process that generates a shell that accepts commands. The window manager then denies any further responsibility and passes the child process to init. Using this mechanism, it is possible to change window managers without interrupting running applications.
Every now and then things go wrong, even in good families. In an exceptional case, a process might finish while the parent does not wait for the completion of this process. Such an unburied process is called a zombie process.
When a process ends normally (it is not killed or otherwise unexpectedly interrupted), the program returns its exit status to the parent. This exit status is a number returned by the program providing the results of the program's execution. The system of returning information upon executing a job has its origin in the C programming language in which UNIX has been written.
The return codes can then be interpreted by the parent, or in scripts. The values of the return codes are program-specific. This information can usually be found in the man pages of the specified program, for example the grep command returns -1 if no matches are found, upon which a message on the lines of “No files found” can be printed. Another example is the Bash builtin command true, which does nothing except return an exit status of 0, meaning success.
Processes end because they receive a signal. There are multiple signals that you can send to a process. Use the kill command to send a signal to a process. The command kill -l shows a list of signals. Most signals are for internal use by the system, or for programmers when they write code. As a user, you will need the following signals:
You can read more about default actions that are taken when sending a signal to a process in man 7 signal.
As promised in the previous chapter, we will now discuss the special modes SUID and SGID in more detail. These modes exist to provide normal users the ability to execute tasks they would normally not be able to do because of the tight file permission scheme used on UNIX based systems. In the ideal situation special modes are used as sparsely as possible, since they include security risks. Linux developers have generally tried to avoid them as much as possible. The Linux ps version, for example, uses the information stored in the /proc file system, which is accessible to everyone, thus avoiding exposition of sensitive system data and resources to the general public. Before that, and still on older UNIX systems, the ps program needed access to files such as /dev/mem and /dev/kmem, which had disadvantages because of the permissions and ownerships on these files:
rita:~> ls -l /dev/*mem
crw-r----- 1 root kmem 1, 2 Aug 30 22:30 /dev/kmem
crw-r----- 1 root kmem 1, 1 Aug 30 22:30 /dev/mem
With older versions of ps, it was not possible to start the program as a common user, unless special modes were applied to it.
While we generally try to avoid applying any special modes, it is sometimes necessary to use an SUID. An example is the mechanism for changing passwords. Of course users will want to do this themselves instead of having their password set by the system administrator. As we know, user names and passwords are listed in the /etc/passwd file, which has these access permissions and owners:
bea:~> ls -l /etc/passwd
-rw-r--r-- 1 root root 1267 Jan 16 14:43 /etc/passwd
Still, users need to be able to change their own information in this file. This is achieved by giving the passwd program special permissions:
mia:~>which passwd passwd is /usr/bin/passwdmia:~>ls -l /usr/bin/passwd -r-s--x--x 1 root root 13476 Aug 7 06:03 /usr/bin/passwd*
When called, the passwd command will run using the access permissions of root, thus enabling a common user to edit the password file which is owned by the system admin.
SGID modes on a file don't occur nearly as frequently as SUID, because SGID often involves the creation of extra groups. In some cases, however, we have to go through this trouble in order to build an elegant solution (don't worry about this too much - the necessary groups are usually created upon installation). This is the case for the write and wall programs, which are used to send messages to other users' terminals (ttys). The write command writes a message to a single user, while wall writes to all connected users.
Sending text to another user's terminal or graphical display is normally not allowed. In order to bypass this problem, a group has been created, which owns all terminal devices. When the write and wall commands are granted SGID permissions, the commands will run using the access rights as applicable to this group, tty in the example. Since this group has write access to the destination terminal, also a user having no permissions to use that terminal in any way can send messages to it.
In the example below, user joe first finds out on which terminal his correspondent is connected, using the who command. Then he sends her a message using the write command. Also illustrated are the access rights on the write program and on the terminals occupied by the receiving user: it is clear that others than the user owner have no permissions on the device, except for the group owner, which can write to it.
joe:~>which write write is /usr/bin/writejoe:~>ls -l /usr/bin/write -rwxr-sr-x 1 root tty 8744 Dec 5 00:55 /usr/bin/write*joe:~>who jenny tty1 Jan 23 11:41 jenny pts/1 Jan 23 12:21 (:0) jenny pts/2 Jan 23 12:22 (:0) jenny pts/3 Jan 23 12:22 (:0) joe pts/0 Jan 20 10:13 (lo.callhost.org)joe:~>ls -l /dev/tty1 crw--w---- 1 jenny tty 4, 1 Jan 23 11:41 /dev/tty1joe:~>write jenny tty1 hey Jenny, shall we have lunch together? ^C
User jenny gets this on her screen:
Message from joe@lo.callhost.org on ptys/1 at 12:36 ... hey Jenny, shall we have lunch together? EOF
After receiving a message, the terminal can be cleared using the Ctrl+L key combination. In order to receive no messages at all (except from the system administrator), use the mesg command. To see which connected users accept messages from others use who -w. All features are fully explained in the Info pages of each command.
Group names may vary
The group scheme is specific to the distribution. Other distributions may use other names or other solutions.